fuel-dev team mailing list archive
-
 fuel-dev team
fuel-dev team
-
Mailing list archive
-
Message #00083
Re: Re-thinking deployment in orchestrator
+ fuel-dev
Dmitry,
thanks for bringing this up. Let's see if it refers with our Reset
Environment feature and can be considered as part of it's design, or Reset
Environment will depend on this.
Thanks,
On Wed, Nov 27, 2013 at 4:27 PM, Dmitry Pyzhov <dpyzhov@xxxxxxxxxxxx> wrote:
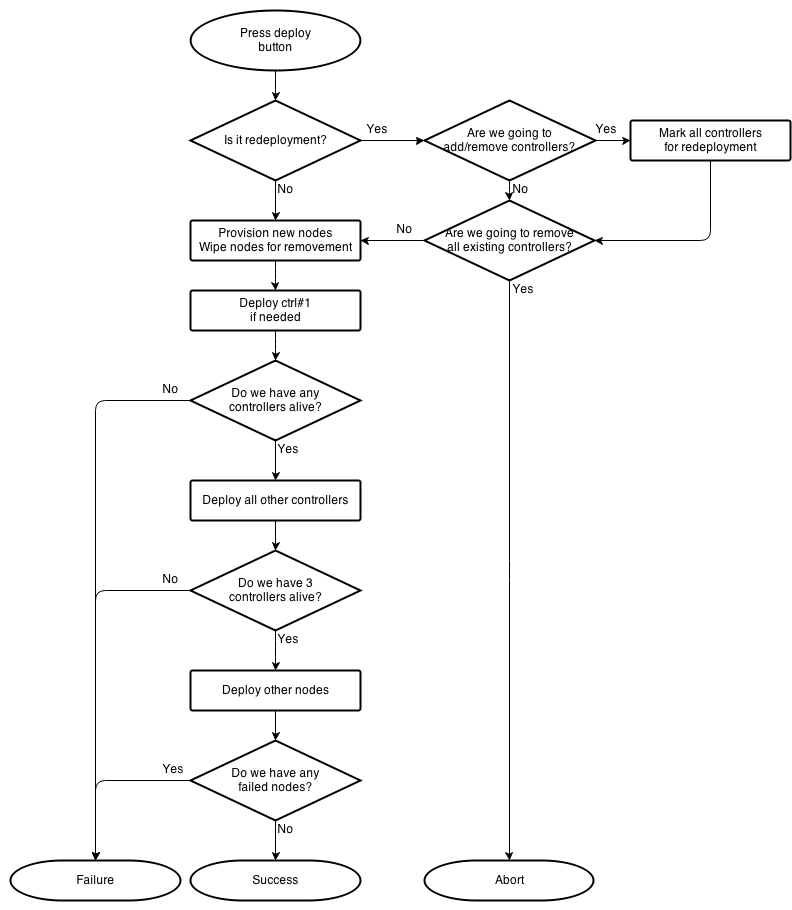
> Guys,
>
> Looks like we should change our deployment sequence. First of all, it
> tries to continue deployment of cluster even if all controllers are dead.
> Second issue: we re-deploy all controllers if we have any change on any
> controller.
>
> AFAIK, our current limitations are:
> 1) We can not redeploy HA controllers without downtime
> 2) We can not correctly schedule removal of one controller and
> installation of another. So we can not move all of our controllers to new
> machines.
> 3) Our deployment sequence is not documented, not designed, not
> well-discussed.
>
> I want to understand, if we need to create blueprint, design, communicate
> and do-it-like-big-boys. Or we can implement following schema, put it into
> documentation and be happy until 'Zero downtime' feature force us to make
> some changes.
>
> [image: Inline image 1]
>
--
Mike Scherbakov
#mihgen