maria-developers team mailing list archive
-
 maria-developers team
maria-developers team
-
Mailing list archive
-
Message #07482
[GSoC] Optimize mysql-test-runs - Analyzing some data
Hello Elena and all,
I have spent a couple of days writing up some scripts to analyze the data,
and try to find good candidates for metrics to improve recall, or some
vices in the way the relevance is calculated for tests, such that they are
not close enough in the priority queue to be spotted and run.
Here's a writedown of some of the findings:
*Of the failures that we miss, how many of them come from tests that have
never failed before?*
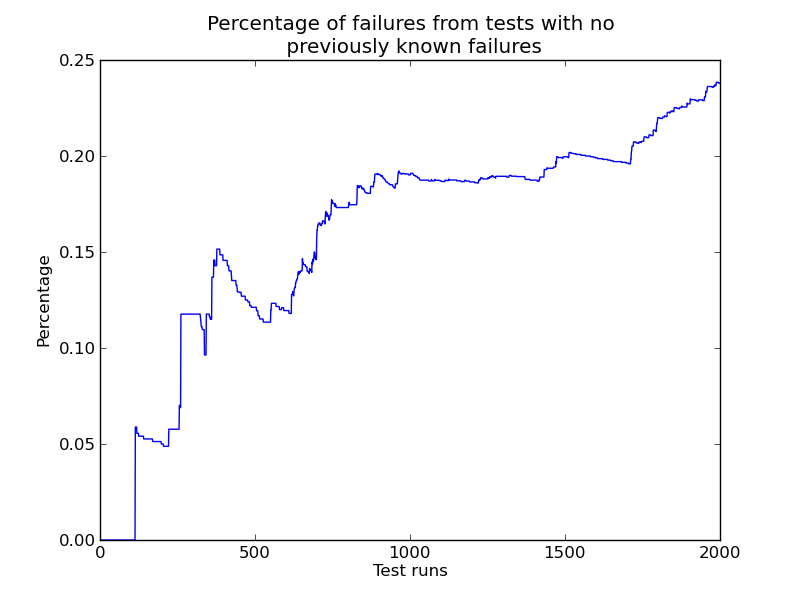
I added a small function in the simulator.py code, to keep diagnostics data
of the test failures that we missed. I made a few charts regarding missed
failures of tests that have never failed before (and, in the current model,
we can't calculate a relevancy for them, because we have no data about
them). In the next chart, we observe the percentage of missed failures that
come from tests that had never failed before increases with time (as
expected):
By the way, this info comes from a standard run with 3000 learning cycles
and 2000 prediction cycles. I feel that this is an important area. If we
can figure a way to predict failures of tests that have not failed before,
then we can predict subsequent failures of these tests, and thus improve
recall significantly, specially over the long term. On the next section I
analyze the option that I considered.
*Is there a relationship between a test file being modified and the test
failing any soon?*
I figured that a good idea to catch failures of tests that had never failed
before could be using the test file changes. If a test file is changed, I
figured that the test itself would change behavior and might fail soon, and
thus we could gather some data about that failure.
I coded a small script that computes the number of test runs between a test
file being edited, and the same test failing sometime in the future. The
relationship, unfortunately is not very strong. I have attached the chart
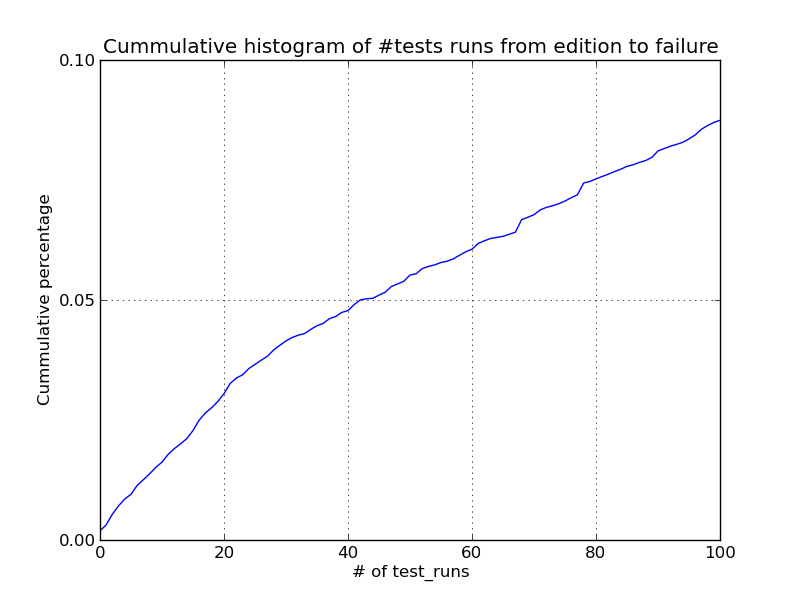
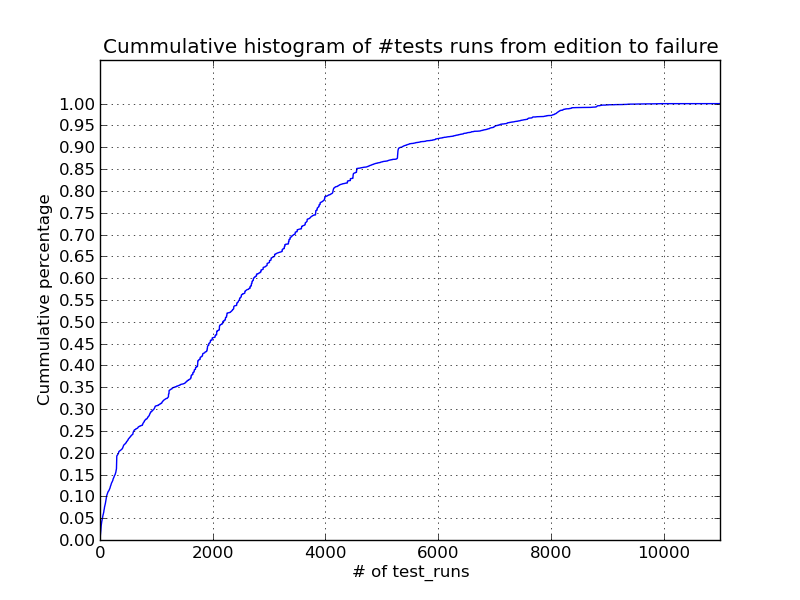
with the cummulative histogram of number of test runs that occurred between
a test file being edited, and the next failure of that test. Unfortunately,
the results were not too exciting. It turns out that tests don't tend to
fail too soon after they have been changed (I guess this also makes sense).
The following figures present the data (and a zoom in of the part of the
graph we care most about), showing that failures are not very subsequent to
test file editions. Not even 10% of failures occur in the first 100 runs.
As we can see from the charts, there is not a very significant relationship
between test file edition and subsequent failure. It seems this indicator
won't be too useful.
I am* still looking for ideas* on how to catch tests failing for the first
time. They are all welcome : )
This is all the data that I collected so far. I am also trying to answer
the following question: Failures of tests with non-zero relevance. How come
we are missing those that we are missing? I have collected and charted some
data, but I still haven't found anything that feels conclusive or
revealing. I expect to write an email with that info soon as well, but I
decided to send this out first.
In conclusion:
- I am thinking about how to predict first failures of a test. Any ideas?
- I tested the relation between edition of a test result file and
subsequent test failure. It was not a good predictor.
Regards
Pablo