| Thread Previous • Date Previous • Date Next • Thread Next |
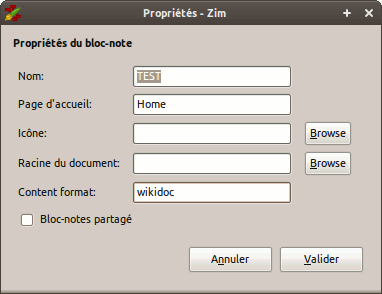
Le lundi 24 janvier 2011 à 09:35 +0100, Jaap Karssenberg a écrit : > I think this should be a notebook property, as different notebooks may > have different default syntax. As such it could be in the notebook > properties dialog. Using a commandline option is not really the right > way, because that would not work when zim is called e.g. from the > desktop application menu. As for coding style I would not use a > parameter WIKI_SYNTAX in all capitals as that suggests a constant, > while in this case this will be a configuration parameter. yes, i get the point. Here's what i've done : - change the name 'wiki_syntax' => 'format' (maybe not a good choice) - Add it as a new notebook configuration parameter (default is 'wiki') - Add a new item in Notebook properties - Change code in a couple of classes where wiki format is needed - And, of course, add a new format module (zim/formats/wikidoc.py) You can see changes in the attached patch file and the notebook properties dialog in the attached screenshot. What i still have to do is to update the page rendering when i change the format value in the notebook properties dialog. > To make things more complicated you might want to think about pages > that do not follow the default. The zim text files have a heading that > gives the wiki format. Ideally for other formats these headings should > still be there but now tell the notebook what alternative syntax they > use. THis would mean the default syntax is only used explicitly when > creating a new page. Yes, that's a complementary way to deal with other wiki syntaxes. I'll see what it can be done with the 'Wiki-Format' header without breaking it all. > So apart from a module for parsing the format you may also need to > subclass the store/files.py module to fine tune it for your specific > file layout. My file layout is a little more complicated than a zim notebook file (http://omacronides.com/projets/phprnb/#doc), dividing file content into "fields" the way AsciiDoc defines document attributes. The purpose is to be able to have some taxonomy information as date, categories and tags, to store those taxonomies into a json index file (quite the same function as the index.db in Zim) and to be able to build documents lists filtered with those taxonomies. But this will be another step (hacking Zim or change my file layout, storing those informations in headers). BTW, it's my first dive into Zim code and i find it pleasant to hack. Thanks Jaap. Regards, -- Rui Nibau Développeur web, rédacteur scientifique email : rui.nibau@xxxxxxxxxxxxxxx jabber: rui.nibau@xxxxxxxxxxxxxxx site : http://omacronides.com pgp : http://omacronides.com/services/pgp-public-key/
# Bazaar merge directive format 2 (Bazaar 0.90)
# revision_id: rui.nibau@xxxxxxxxxxxxxxx-20110124205042-\
# nfdescmq2kejolui
# target_branch: file:///home/rnb/apps/src/zim/
# testament_sha1: ba468eb4e7687ee1bbaf1e1228383d5504bf29a3
# timestamp: 2011-01-24 21:50:49 +0100
# base_revision_id: rui.nibau@xxxxxxxxxxxxxxx-20110122151518-\
# 2xjs353o8g5z7fhn
#
# Begin patch
=== added file 'zim/formats/wikidoc.py'
--- zim/formats/wikidoc.py 1970-01-01 00:00:00 +0000
+++ zim/formats/wikidoc.py 2011-01-24 20:46:53 +0000
@@ -0,0 +1,508 @@
+# -*- coding: utf-8 -*-
+
+# Copyright 2008 Jaap Karssenberg <pardus@xxxxxxxx>
+
+# Parts of this file has been modified by Rui Nibau <rui.nibau@xxxxxxxxxxxxxxx>
+# The new Parser / Dumper have to deal with :
+# http://omacronides.com/projets/syntaxe-wiki/
+# - setext headings DONE
+# - change in link attrs order DONE
+# - change in image markup DONE
+# - change in emphasis, strike and code markup DONE
+# - add cite markup TODO
+# - add Description list block TODO ?
+# - add blockquote markup TODO ?
+# - change pre / verbatim markup TODO ?
+# - add Table markup TODO ? gtkTreeView ? Ouch !
+# - add figure markup TODO ? content + legend useful in Zim ?
+# - add (foot|side)notes markup TODO ? How to do it in gtk ?
+
+# Maybe it's not necessary to parse all markup when viewing / editing files in Zim
+
+'''This module handles parsing and dumping wiki text'''
+
+import re
+
+from zim.formats import *
+from zim.parsing import Re, TextBuffer, url_re
+
+
+WIKI_FORMAT_VERSION = 'zim 0.4'
+
+
+info = {
+ 'name': 'Wiki text',
+ 'mime': 'text/x-zim-wiki',
+ 'read': True,
+ 'write': True,
+ 'import': True,
+ 'export': True,
+}
+
+TABSTOP = 4
+bullet_re = u'[\\*\u2022]|\\[[ \\*x]\\]'
+ # bullets can be '*' or 0x2022 for normal items
+ # and '[ ]', '[*]' or '[x]' for checkbox items
+
+bullets = {
+ '[ ]': UNCHECKED_BOX,
+ '[x]': XCHECKED_BOX,
+ '[*]': CHECKED_BOX,
+ '*': BULLET,
+}
+# reverse dict
+bullet_types = {}
+for bullet in bullets:
+ bullet_types[bullets[bullet]] = bullet
+
+parser_re = {
+ 'blockstart': re.compile("^(\t*''')\s*?\n", re.M),
+ 'pre': re.compile("^(?P<escape>\t*''')\s*?(?P<content>^.*?)^(?P=escape)\s*\n", re.M | re.S),
+ 'splithead': re.compile('^(==+[ \t]+\S.*?\n)', re.M),
+ 'heading': re.compile("\A((==+)[ \t]+(.*?)([ \t]+==+)?[ \t]*\n?)\Z"),
+ 'splitlist': re.compile("((?:^[ \t]*(?:%s)[ \t]+.*\n?)+)" % bullet_re, re.M),
+ 'listitem': re.compile("^([ \t]*)(%s)[ \t]+(.*\n?)" % bullet_re),
+ 'unindented_line': re.compile('^\S', re.M),
+ 'indent': re.compile('^(\t+)'),
+
+ # All the experssions below will match the inner pair of
+ # delimiters if there are more then two characters in a row.
+ 'link': Re('\[\[(?!\[)(.+?)\]\]'),
+ # XXX change from {{ to ((
+ 'img': Re('\(\((?!\()(.+?)\)\)'),
+ # XXX change from // to ''
+ 'emphasis': Re("''(?!')(.+?)''"),
+ 'strong': Re('\*\*(?!\*)(.+?)\*\*'),
+ 'mark': Re('__(?!_)(.+?)__'),
+ 'sub': Re('_\{(?!~)(.+?)\}'),
+ 'sup': Re('\^\{(?!~)(.+?)\}'),
+ # XXX change from ~~ to --
+ 'strike': Re('--(?!-)(.+?)--'),
+ # XXX change from '' to @@
+ 'code': Re("@@(?!@)(.+?)@@"),
+}
+
+# patterns to match setext headings
+parser_setext_headers = re.compile("(.+?)\n(=|-|\.|'){5,}$", re.M)
+parser_setext_h1 = re.compile("^[=]{5,}\n(.+?)\n[=]{5,}$", re.M)
+setext_headers_map = { '=':2, '-':3, '.':4, "'":5 }
+
+dumper_tags = {
+ # XXX change from // to ''
+ 'emphasis': "''",
+ 'strong': '**',
+ 'mark': '__',
+ # XXX change from ~~ to --
+ 'strike': '--',
+ # XXX change from '' to @@
+ 'code': "@@",
+}
+
+
+def contains_links(text):
+ '''Optimisation for page.get_links()'''
+ for line in text:
+ if '[[' in line:
+ return True
+ else:
+ return False
+
+def get_key_by_value(dic, value):
+ '''
+ get the key of a value in a dictionary
+ @param {Dict} dic Dictionary where to find the key
+ @param {Mixed} value Value to search for
+ @return {Mixed} The key associated with the value
+ '''
+ return [k for k, v in dic.iteritems() if v == value][0]
+
+class Parser(ParserClass):
+
+ def __init__(self, version=WIKI_FORMAT_VERSION):
+ self.backward = version not in ('zim 0.26', WIKI_FORMAT_VERSION)
+
+ def parse(self, input):
+ # Read the file and divide into paragraphs on the fly.
+ # Blocks of empty lines are also treated as paragraphs for now.
+ # We also check for blockquotes here and avoid splitting them up.
+ if isinstance(input, basestring):
+ input = input.splitlines(True)
+
+ paras = ['']
+ def para_start():
+ # This function is called when we suspect the start of a new paragraph.
+ # Returns boolean for success
+ if len(paras[-1]) == 0:
+ return False
+ blockmatch = parser_re['blockstart'].search(paras[-1])
+ if blockmatch:
+ quote = blockmatch.group()
+ blockend = re.search('\n'+quote+'\s*\Z', paras[-1])
+ if not blockend:
+ # We are in a block that is not closed yet
+ return False
+ # Else append empty paragraph to start new para
+ paras.append('')
+ return True
+
+ def blocks_closed():
+ # This function checks if there are unfinished blocks in the last
+ # paragraph.
+ if len(paras[-1]) == 0:
+ return True
+ # Eliminate closed blocks
+ nonblock = parser_re['pre'].split(paras[-1])
+ # Blocks are closed if none is opened at the end
+ return parser_re['blockstart'].search(nonblock[-1]) == None
+
+ para_isspace = False
+ for line in input:
+ # Try start new para when switching between text and empty lines or back
+ if line.isspace() != para_isspace and blocks_closed():
+ if para_start():
+ para_isspace = line.isspace() # decide type of new para
+ paras[-1] += line
+
+ # Now all text is read, start wrapping it into a document tree.
+ # Headings can still be in the middle of a para, so get them out.
+ builder = TreeBuilder()
+ builder.start('zim-tree')
+ for para in paras:
+ # HACK this char is recognized as line end by splitlines()
+ # but not matched by \n in a regex. Hope there are no other
+ # exceptions like it (crosses fingers)
+ para = para.replace(u'\u2028', '\n')
+
+ if self.backward and not para.isspace() \
+ and not parser_re['unindented_line'].search(para):
+ self._parse_block(builder, para)
+ else:
+ block_parts = parser_re['pre'].split(para)
+ for i, b in enumerate(block_parts):
+ if i % 3 == 0:
+ # Text paragraph
+ parts = parser_re['splithead'].split(b)
+ for j, p in enumerate(parts):
+ if j % 2:
+ # odd elements in the list are headings after split
+ self._parse_head(builder, p)
+ elif len(p) > 0:
+ # XXX setext heading
+ if not self._parse_setext_head(builder, p):
+ self._parse_para(builder, p)
+ elif i % 3 == 1:
+ # Block
+ self._parse_block(builder, b + '\n' + block_parts[i+1] + b + '\n')
+
+ builder.end('zim-tree')
+ return ParseTree(builder.close())
+
+ def _parse_block(self, builder, block):
+ '''Parse a block, like a verbatim paragraph'''
+ if not self.backward:
+ m = parser_re['pre'].match(block)
+ if not m:
+ logger.warn('Block does not match pre >>>\n%s<<<', block)
+ builder.data(block)
+ else:
+ indent = self._determine_indent(block)
+ block = m.group('content')
+ if indent > 0:
+ builder.start('pre', {'indent': indent})
+ block = ''.join(
+ map(lambda line: line[indent:], block.splitlines(True)))
+ else:
+ builder.start('pre')
+ builder.data(block)
+ builder.end('pre')
+ else:
+ builder.start('pre')
+ builder.data(block)
+ builder.end('pre')
+
+
+ def _parse_head(self, builder, head):
+ '''Parse a heading'''
+ m = parser_re['heading'].match(head)
+ assert m, 'Line does not match a heading: %s' % head
+ level = 7 - min(6, len(m.group(2)))
+ builder.start('h', {'level': level})
+ builder.data(m.group(3))
+ builder.end('h')
+ builder.data('\n')
+
+ def _parse_setext_head(self, builder, head):
+ '''
+ Parse setext headings
+ Returns boolean If it's a setext header or not
+ '''
+ ishead = False
+ text = ""
+ # heading level 2 - 6
+ m = parser_setext_headers.match(head)
+ if m:
+ level = setext_headers_map[m.group(2)]
+ text = m.group(1)
+ ishead = True
+ else:
+ # heading level 1
+ m = parser_setext_h1.match(head)
+ if m:
+ level = 1
+ text = m.group(1)
+ ishead = True
+ if ishead:
+ builder.start('h', {'level': level})
+ builder.data(text)
+ builder.end('h')
+ builder.data('\n')
+
+ return ishead
+
+ def _parse_para(self, builder, para):
+ '''Parse a normal paragraph'''
+ if para.isspace():
+ builder.data(para)
+ return
+
+ builder.start('p')
+
+ parts = parser_re['splitlist'].split(para)
+ for i, p in enumerate(parts):
+ if i % 2:
+ # odd elements in the list are lists after split
+ self._parse_list(builder, p)
+ elif len(p) > 0:
+ # non-list part of the paragraph
+ indent = 0
+ for line in p.splitlines(True):
+ # parse indenting per line...
+
+ m = parser_re['indent'].match(line)
+ if m: myindent = len(m.group(1))
+ else: myindent = 0
+
+ if myindent != indent:
+ if indent > 0:
+ builder.end('div')
+ if myindent > 0:
+ builder.start('div', {'indent': myindent})
+ indent = myindent
+
+ self._parse_text(builder, line[indent:])
+
+ if indent > 0:
+ builder.end('div')
+
+ builder.end('p')
+
+ def _determine_indent(self, text):
+ lvl = 999 # arbitrary large value
+ for line in text.splitlines():
+ m = parser_re['indent'].match(line)
+ if m:
+ lvl = min(lvl, len(m.group(1)))
+ else:
+ return 0
+ return lvl
+
+ def _parse_list(self, builder, list):
+ '''Parse a bullet list'''
+
+ indent = self._determine_indent(list)
+ lines = list.splitlines()
+ if indent > 0:
+ lines = [line[indent:] for line in lines]
+ builder.start('ul', {'indent': indent})
+ else:
+ builder.start('ul')
+
+ level = 0 # relative to indent
+ for line in lines:
+ m = parser_re['listitem'].match(line)
+ assert m, 'Line does not match a list item: >>%s<<' % line
+ prefix, bullet, text = m.groups()
+
+ mylevel = prefix.replace(' '*TABSTOP, '\t').count('\t')
+ if mylevel > level:
+ for i in range(level, mylevel):
+ builder.start('ul')
+ elif mylevel < level:
+ for i in range(mylevel, level):
+ builder.end('ul')
+ level = mylevel
+
+ if bullet in bullets:
+ attrib = {'bullet': bullets[bullet]}
+ else:
+ attrib = {'bullet': '*'}
+ builder.start('li', attrib)
+ self._parse_text(builder, text)
+ builder.end('li')
+
+ for i in range(-1, level):
+ builder.end('ul')
+
+ def _parse_text(self, builder, text):
+ '''Parse a piece of rich text, handles all inline formatting'''
+ list = [text]
+ list = parser_re['code'].sublist(
+ lambda match: ('code', {}, match[1]), list)
+
+ # XXX change link attrs order : from link|text to text|link
+ def parse_link(match):
+ parts = match[1].split('|', 2)
+ link = parts[0]
+ mytext = parts[0]
+ if len(parts) > 1:
+ link = parts[1]
+ if len(mytext) == 0: # [[|link]] bug
+ mytext = link
+ return ('link', {'href':link}, mytext)
+
+ list = parser_re['link'].sublist(parse_link, list)
+
+ def parse_image(match):
+ parts = match[1].split('|', 2)
+ src = parts[0]
+ if len(parts) > 1: mytext = parts[1]
+ else: mytext = None
+ attrib = self.parse_image_url(src)
+ return ('img', attrib, mytext)
+
+ list = parser_re['img'].sublist(parse_image, list)
+
+
+ # Put URLs here because urls can appear in links or image tags, but other markup
+ # can appear in links, like '//' or '__'
+ list = url_re.sublist(
+ lambda match: ('link', {'href':match[1]}, match[1]) , list)
+
+ for style in 'strong', 'mark', 'strike','sub', 'sup':
+ list = parser_re[style].sublist(
+ lambda match: (style, {}, match[1]) , list)
+
+ for style in 'emphasis',:
+ list = parser_re[style].sublist(
+ lambda match: (style, {}, match[1]) , list)
+
+ for item in list:
+ if isinstance(item, tuple):
+ tag, attrib, text = item
+ builder.start(tag, attrib)
+ builder.data(text)
+ builder.end(tag)
+ else:
+ builder.data(item)
+
+
+class Dumper(DumperClass):
+
+ # TODO check commonality with dumper in plain.py
+
+ def dump(self, tree):
+ #~ print 'DUMP WIKI', tree.tostring()
+ assert isinstance(tree, ParseTree)
+ output = TextBuffer()
+ self.dump_children(tree.getroot(), output)
+ return output.get_lines(end_with_newline=not tree.ispartial)
+
+ def dump_children(self, list, output, list_level=-1):
+ if list.text:
+ output.append(list.text)
+
+ for element in list.getchildren():
+ if element.tag in ('p', 'div'):
+ indent = 0
+ if 'indent' in element.attrib:
+ indent = int(element.attrib['indent'])
+ myoutput = TextBuffer()
+ self.dump_children(element, myoutput) # recurs
+ if indent:
+ myoutput.prefix_lines('\t'*indent)
+ output.extend(myoutput)
+ elif element.tag == 'ul':
+ indent = 0
+ if 'indent' in element.attrib:
+ indent = int(element.attrib['indent'])
+ myoutput = TextBuffer()
+ self.dump_children(element, myoutput, list_level=list_level+1) # recurs
+ if indent:
+ myoutput.prefix_lines('\t'*indent)
+ output.extend(myoutput)
+ elif element.tag == 'h':
+ # XXX change to use setext headings
+ level = int(element.attrib['level'])
+ if level < 1: level = 1
+ elif level > 5: level = 5
+ tag = '='*(7 - level)
+ # build output
+ start = ''
+ end = ''
+ if level == 1:
+ start = ('='*80)+'\n'
+ end = '\n'+('='*80)
+ else:
+ end = '\n'+(get_key_by_value(setext_headers_map, level)*80)
+ output.append(start+element.text+end)
+ elif element.tag == 'li':
+ if 'indent' in element.attrib:
+ list_level = int(element.attrib['indent'])
+ if 'bullet' in element.attrib:
+ bullet = bullet_types[element.attrib['bullet']]
+ else:
+ bullet = '*'
+ output.append('\t'*list_level+bullet+' ')
+ self.dump_children(element, output, list_level=list_level) # recurs
+ output.append('\n')
+ elif element.tag == 'pre':
+ indent = 0
+ if 'indent' in element.attrib:
+ indent = int(element.attrib['indent'])
+ myoutput = TextBuffer()
+ myoutput.append("'''\n"+element.text+"'''\n")
+ if indent:
+ myoutput.prefix_lines('\t'*indent)
+ output.extend(myoutput)
+ elif element.tag == 'img':
+ src = element.attrib['src']
+ opts = []
+ for k, v in element.attrib.items():
+ if k == 'src' or k.startswith('_'):
+ continue
+ else:
+ opts.append('%s=%s' % (k, v))
+ if opts:
+ src += '?%s' % '&'.join(opts)
+ if element.text:
+ output.append('(('+src+'|'+element.text+'))')
+ else:
+ output.append('(('+src+'))')
+ elif element.tag == 'sub':
+ output.append("_{%s}" % element.text)
+ elif element.tag == 'sup':
+ output.append("^{%s}" % element.text)
+ elif element.tag == 'link':
+ assert 'href' in element.attrib, \
+ 'BUG: link %s "%s"' % (element.attrib, element.text)
+ href = element.attrib['href']
+ if href == element.text:
+ if url_re.match(href):
+ output.append(href)
+ else:
+ output.append('[['+href+']]')
+ else:
+ if element.text:
+ output.append('[['+element.text+'|'+href+']]')
+ else:
+ output.append('[['+href+']]')
+
+ elif element.tag in dumper_tags:
+ if element.text:
+ tag = dumper_tags[element.tag]
+ output.append(tag+element.text+tag)
+ else:
+ assert False, 'Unknown node type: %s' % element
+
+ if element.tail:
+ output.append(element.tail)
=== modified file 'zim/gui/clipboard.py'
--- zim/gui/clipboard.py 2011-01-16 18:05:42 +0000
+++ zim/gui/clipboard.py 2011-01-24 20:17:10 +0000
@@ -185,6 +185,7 @@
def _get_parsetree_data(self, selectiondata, id, data):
logger.debug("Cliboard data request of type '%s', we have a parsetree", selectiondata.target)
notebook, page, parsetree = data
+ ft = notebook.config['Notebook'].get('format')
if id == PARSETREE_TARGET_ID:
xml = parsetree.tostring().encode('utf-8')
selectiondata.set(PARSETREE_TARGET_NAME, 8, xml)
@@ -193,9 +194,9 @@
# around glitches in pageview parsetree dumper
# main visibility when copy pasting bullet lists
# Same hack in print to browser plugin
- dumper = get_format('wiki').Dumper()
+ dumper = get_format(ft).Dumper()
text = ''.join( dumper.dump(parsetree) ).encode('utf-8')
- parser = get_format('wiki').Parser()
+ parser = get_format(ft).Parser()
parsetree = parser.parse(text)
#--
dumper = get_format('html').Dumper(
@@ -207,7 +208,7 @@
elif id == TEXT_TARGET_ID:
# FIXME no using wiki although plain is preferred
# because plain does not yet support lists etc.
- dumper = get_format('wiki').Dumper()
+ dumper = get_format(ft).Dumper()
text = ''.join( dumper.dump(parsetree) ).encode('utf-8')
selectiondata.set_text(text)
=== modified file 'zim/gui/exportdialog.py'
--- zim/gui/exportdialog.py 2011-01-16 16:57:26 +0000
+++ zim/gui/exportdialog.py 2011-01-24 20:17:10 +0000
@@ -82,12 +82,13 @@
# around glitches in pageview parsetree dumper
# main visibility when copy pasting bullet lists
# Same hack in gui clipboard code
+ ft = self.ui.notebook.config['Notebook'].get('format')
from zim.notebook import Path, Page
from zim.formats import get_format
parsetree = page.get_parsetree()
- dumper = get_format('wiki').Dumper()
+ dumper = get_format(ft).Dumper()
text = ''.join( dumper.dump(parsetree) ).encode('utf-8')
- parser = get_format('wiki').Parser()
+ parser = get_format(ft).Parser()
parsetree = parser.parse(text)
page = Page(Path(page.name), parsetree=parsetree)
=== modified file 'zim/notebook.py'
--- zim/notebook.py 2011-01-16 21:57:51 +0000
+++ zim/notebook.py 2011-01-24 20:50:42 +0000
@@ -377,6 +377,7 @@
('home', 'page', _('Home Page')), # T: label for properties dialog
('icon', 'image', _('Icon')), # T: label for properties dialog
('document_root', 'dir', _('Document Root')), # T: label for properties dialog
+ ('format', 'string', _('Content format')), # T: label for properties dialog
('shared', 'bool', _('Shared Notebook')), # T: label for properties dialog
#~ ('autosave', 'bool', _('Auto-version when closing the notebook')),
# T: label for properties dialog
@@ -442,6 +443,7 @@
self.config['Notebook'].setdefault('home', ':Home', check=basestring)
self.config['Notebook'].setdefault('icon', None, check=basestring)
self.config['Notebook'].setdefault('document_root', None, check=basestring)
+ self.config['Notebook'].setdefault('format', 'wiki')
self.config['Notebook'].setdefault('shared', False)
if os.name == 'nt': endofline = 'dos'
else: endofline = 'unix'
@@ -486,6 +488,13 @@
if 'home' in properties and isinstance(properties['home'], Path):
properties['home'] = properties['home'].name
+ # FIXME check if format exists - if not, back to 'wiki'
+ # XXX How to check if it's a valid format ? Parser instance of ParserClass
+ # and Dumper instance of DumperClass ?
+ ft = properties.get('format')
+ if ft:
+ logger.warning("[rnb] check if zim/formats/[ft].py exists")
+
self.config['Notebook'].update(properties)
self.config.write()
self.emit('properties-changed')
=== modified file 'zim/plugins/printtobrowser.py'
--- zim/plugins/printtobrowser.py 2010-09-10 20:45:48 +0000
+++ zim/plugins/printtobrowser.py 2011-01-24 20:17:10 +0000
@@ -62,12 +62,13 @@
# around glitches in pageview parsetree dumper
# main visibility when copy pasting bullet lists
# Same hack in gui clipboard code
+ ft = self.ui.notebook.config['Notebook'].get('format')
from zim.notebook import Path, Page
from zim.formats import get_format
parsetree = page.get_parsetree()
- dumper = get_format('wiki').Dumper()
+ dumper = get_format(ft).Dumper()
text = ''.join( dumper.dump(parsetree) ).encode('utf-8')
- parser = get_format('wiki').Parser()
+ parser = get_format(ft).Parser()
parsetree = parser.parse(text)
page = Page(Path(page.name), parsetree=parsetree)
#--
=== modified file 'zim/plugins/tasklist.py'
--- zim/plugins/tasklist.py 2011-01-16 16:57:26 +0000
+++ zim/plugins/tasklist.py 2011-01-24 20:46:53 +0000
@@ -192,9 +192,10 @@
# around glitches in pageview parsetree dumper
# make sure we get paragraphs and bullets are nested properly
# Same hack in gui clipboard code
- dumper = get_format('wiki').Dumper()
+ ft = self.ui.notebook.config['Notebook'].get('format')
+ dumper = get_format(ft).Dumper()
text = ''.join( dumper.dump(parsetree) ).encode('utf-8')
- parser = get_format('wiki').Parser()
+ parser = get_format(ft).Parser()
parsetree = parser.parse(text)
#~ print '!! Checking for tasks in', path
=== modified file 'zim/stores/files.py'
--- zim/stores/files.py 2010-12-28 13:48:12 +0000
+++ zim/stores/files.py 2011-01-24 20:17:10 +0000
@@ -44,7 +44,10 @@
if not self.store_has_dir():
raise AssertionError, 'File store needs directory'
# not using assert here because it could be optimized away
- self.format = get_format('wiki') # TODO make configable
+ ft = self.notebook.config['Notebook'].get('format')
+ if ft is None:
+ ft = 'wiki'
+ self.format = get_format(ft) # TODO make configable
def _get_file(self, path):
'''Returns a File object for a notebook path'''
=== modified file 'zim/stores/memory.py'
--- zim/stores/memory.py 2009-08-13 13:21:00 +0000
+++ zim/stores/memory.py 2011-01-24 20:17:10 +0000
@@ -32,7 +32,10 @@
Pass args needed for StoreClass init.
'''
StoreClass.__init__(self, notebook, path)
- self.format = get_format('wiki') # TODO make configable
+ ft = notebook.config['Notebook'].get('format')
+ if ft is None:
+ ft = 'wiki'
+ self.format = get_format(ft) # TODO make configable
self._nodetree = []
self.readonly = False
=== modified file 'zim/stores/xml.py'
--- zim/stores/xml.py 2011-01-20 17:24:53 +0000
+++ zim/stores/xml.py 2011-01-24 20:17:10 +0000
@@ -42,7 +42,10 @@
if not self.store_has_file():
raise AssertionError, 'XMl store needs file'
# not using assert here because it could be optimized away
- self.format = get_format('wiki') # FIXME store format in XML header
+ ft = notebook.config['Notebook'].get('format')
+ if ft is None:
+ ft = 'wiki'
+ self.format = get_format() # FIXME store format in XML header
if self.file.exists():
self.parse(self.file.read())
# Begin bundle
IyBCYXphYXIgcmV2aXNpb24gYnVuZGxlIHY0CiMKQlpoOTFBWSZTWfFClS8AFpb/gH43GOB////3
///f37////9gJtwD73qem5u9nu7bvIHSjq69Pe93hreee7a9bvtp061SRUKoAUC5gPp3fM+6W2++
8+fc7HY5b7dd1sqfLy+tPR9dvXe7uFcd9cLt7d2uhXLFu7dEVXdy2Z9931UY8YdRU+UwkiICaNBo
KejTJiqf6BU9tIp+nqapsnlPVHiNkkAaekHlHlNiQJQQBAEIxEZI9TNQ1T9NNUaepp6jJ6m1A0GR
kB6hpoB6DTTQhNQ1KfqNMp6amgPSaA0GajQNAAAAAAGgCTSSQmgKm9J6U8p6nqPJkR6MpiGgGQA0
9TQ0HqNA0AAIlECZBRmk09VP9DSptqngaRH6TaTU/VPTSemoeppkbUNGTEyDQ8oJEghMjQAjTJM0
TEAjyk1PIRkPU/VA0NGhoDE9EDbgJJA3kCAdylRFBggqKhHyCUYqrFUVVjBBSAxSDGCqIILGRRRF
VRioIoiCxREFi1lEYiRWDQLUIsGRVRSKjBABCAwFFQkUBYEhUCpJcSKxZ8XqXzs72xc8VGZXOGfG
ruTb0IX5pdmYHo4Ya33YGH9LLfYvMn59rI+hm/AvPQ5hrDleOUmym1hz/vppnRvuHEj25YU/1xXL
nxrcMqwZ/8zPLIDAztUYTovjWdZkicbXGtAVTgglrFiptE/WKZDMC6f7iLl9Oj9LYE20fH9XyyN1
Qz/8OORdUsKqrmuk9YkBVayu5DsjcX120wtlKBcnelsgPJ55gYMrvOV1L2bOLjsD/5Qzl/raixko
v4yQ54KaqEVD6hRJ3Q0VC1TLS3B/1MxKbJ/w7CUVGUvcYlRjmoSXwpl9n2Q/9k1uWvPt05os2v7H
hUGSoTheYXEMQ0xkvR5GFd+NvTUyMhdGoov6ximHFf467bvznTEn6Nf0Kfl/hVG+2VU28G15timK
gOoddqPVO6i7Rgr82eIuzAgXVAOioCRQTFvZmNM+TpKbdHFMSCnl5BbAF7W1cay5cyAWGve7AjmH
5AEfE7PhAWPcKgz8spbXOIhvz33/O7CttJMltgNXqXb97PMkxmi0+7KeJ4EVfhXVPGHOnxeqap6R
8Of8rrMZ+UX9+MrLEFIqKRYazZqjqTiKpCemHi8pH4G6/D4wyri0CODYPpasxeLLvGZCxBiYrBaA
TAqICwFUFFFFWLM2PX2EUFqp4InvUBPZp8Z5+fbkHehxlRZt8trRnQd3dLKTFI1yxP6GsSvl4ls4
p4E8SjmRHNcmZ9Gso8EZJrooJGIdumE4xlu6UHJZyBpNKaiIxjg7EZIrbolemBAYizsQ5bL2Ay/k
iBr5XjAde1hSr8WWeSKKHNMzXivJ8/wZwRgPIxTe8Oaymqs+z03wKKbbkQQOIc2eeXcm6xacvFBc
3XsI4GGhbrDwDl339x9oDMxIc1uim91B86HLp+mhudnZ8GHc9q9KjwmcaqB5/h+uTX1l86FS6bwp
T3QeOMjb4boppA/gVDZcQw/C6Pkopaw5u7p9d1ClkJDLYcMnx/blYiWIFcg+mO5TcQ5mklL4iko2
MyjVXz0a5k6WFJNqhmeUPURH1vxZb4qWML+yYq1fjrhgqNU89KiTjO0P2yMsztaN0uOp4onFFVW7
PJfrF0M8LX4Gztg3JzfwumirmenCfG02ctY6z408uzaKJEmiG0R3SZFmLDpnsdSEV1VBOmrvnp9S
8vhLHvFjS+Y2WQMh3KkAqZaoI9u3hM48XPuxOR2jBPEvFUqhqmvSR4wM5Q52FvVYcYk3gfNPmyoS
9vsJOQVLj/O+0PNHLovPdE5v0NW7YbWGQxiqQVzCuyjG+ArWrHbqCWpsjlfmxtFmbIPiXccktz9q
Q5t6bNkiVffjOmhAi7aKcmGnwoA86s6SaJEIsqesvXCgnGacmwDALkZbPjWD45CqzFEcU/CgldLP
RQWO+nWS+Zd2seoE2xquDgWO+7hO1umzg0xrHa+aYqIs0+UVXM53zFMXyvvXTPPwzy2QSEsUjkgm
KhVmQj00lp8kvv3GilckT7++K9rN7nfMzTJTZANX2kYQVkIe3Y26x02OfTBqR4e1ppCHxDQH6wHT
CBqIVOW9PblaZowC+8Wy1RZvc3hKevMaDPOZb8IG9jeut/k4UgKbROa+MNoQmcfRGSeiR7menJ2e
4/stpXbXnk/RJTX2vl4rSrShWxCC9/ZE17Rhks/OYzq6+vs6uyqTc0vZJaOkINqFWFJg4iKBjuuS
jyiK3X/V+LMTZ+PHp2Gxjy+gN+J8ub1Rd3/AbQgUcVmHFbqETISW70gm72dDZKrKiZmB52B5/g3Y
OWVDbNOba2BIcJBJatdMC1y/Zgwbhl3Qe+yPozr0ujhbfrZft4LlM/PtR6oeWvithbpsUEmGBjbH
wHSN0kXtlI4t+ZU0lLMBuQe/Z1yrL2t1TvtzI4iqEgG8XPHfzgnqLD4eIP9mN/Vx72hLKGh+TY7F
9SqLMNiPIVW5Gdsp7afTy6fjl8FyPrpc+z5bvvt/ZeceXDrJHf0m98f9Y2bLNPpGVsxnhLXTG66y
HEbxuqKa3y5YQHGVIxLnzezkL+EY2uOtIGNJ1qZdT81zA0errBFGtQ24eTd0dLO5J1dmdiY67MxN
tZzzmhzj0dJnlLrRbNLkpCoNy6LrWstB1MIjo0mrlbQwBuS7o1cWiJ7zVm0G6sLlTeJ8neHzs5+c
OcYU8NoaItus8aqgP8p6r+KnRTZbymVQYuBk4iBxEEDFWtS9h/D4fNw9+c3XaqQ5uKYb7nLq1zq1
fkHWK1I6tJPZZ9IXeHzyS5MmUhHy0lheT3LHMBlWXDvxjjdoPHIeFnTCcpANx4aTacO/E8NasAW0
oQ0UWqiiUHBEiqEUYl7dCOpbQEVcbKweO+egn6pxv9aRmPXhDucn/EyXrRGJ/Dfyeumbylhes5Er
GbsbKwpVvDVZY3pacdG+za3yQ1i2lm0xIO9GQeOmMGhk4zsKKqNk4LWa/z0l4TsFLW4Gz6vuILB6
oswRD2msqdnJnrNEd/TXs2Tx2dxqqq8WB/Q1FRlk4IYtdMAyJm6d4gUM9rnhToISdfTQwOkSPk/d
BIq/k3rLV9XyO2DcV+KTWPDRWOyQtBWDeyJeDLSvXJRsHHYPc7/kNxQkSKy7CINZCyeyuHRHhOos
n95Dp9Nh8UQi0e+pTuVhFWyL8E6Kpiqm5DGt/z7udvxeubuB+lAo+Z50fZ4ZkH15Cf09KVpMlw+v
1t6q+U+DdU1ha6e8LMYvVz+7egmrpTL49fhnwyWma5vfLQvVSiWA1813HfsSGwgm/ySCyJwH6u+n
868MHizxZ1JEgSd+FmbQPxbeZKc8ayKogN7A4yjQHmAtaBFR8j3dBm+UIWJ3Di4BoqIF1EGwOsMl
1hOoiYvpCYl4O8zBAZlvYRJ0Y/RQTzffc5X6J+De825/IyRLTjra+xZpFIkwN4BGddQwShcpAATE
eKU60SIBgqqFv+KLWTtbnuYELmez2bS3i8lkLmABgzrQRflUqHP24EdF9Pux4ICjlChMkTCgejfT
AQimHhVBGhFQokKM6oemn2HzG2bf6IQtZyW4Y7LJS3bssRAERCiIspQ2YyyCfkeXXwigkHk5VgBe
piLGFeyoXscIo2tlalpeI8ZFK94KFhc0UAoTQgIGWigSsYhXGJWs4dGqel1SpcyCAlYbARSCQREZ
pCDiKTvz9PjEpEyJ1KmBEgWBWMwCoDHMgqWGgSYSBWiCChnSLUIOgfMGJ7+mZuZClzM1NiUcwwD6
CIeg0BCSROElfEJFkSkD79FUgw8TyZIvrbt0hcjBApfqxzANpCWpmOghG2h0GEL1nQBPsDNXLYhA
dqDFDqMdjGBILBcJEDAve9NRUYFUkMiCJwLoagxAh0qU2Ns5TtFb1dtArjRSHDOr8AJXmYrO85Gt
CMnAwKgXFvrDaFmtG1NYIxyCM9GUxs1VEYFwm0Ousz410q6VJiFEsJnstVgKsyppfHLG6sRaiUkj
EczQOEYgYoXI5cQZFRQ5m5Yma2gcBOJiYH0HUqd/axwQEqJsutqTIebGcpq3LYEzrOVtrSmUQIWO
eaSCnl/ISOEWBDAyLYqxUcgjxJQIokQfPgU0lHmZEzdDkRwS4UDGI7ogiT9MOmEuzMYxMrjD3KXO
9atcMCB3w3K4kdLoQg4t4kQoMxuKKbne4iFa7F9DQgvQ24Dim5CNRjOI0CBapG8D4/HsTwD0C9Ko
yHEOexXue7SSNnq9Wo5CwGkukL5zDkwlIXo5cwQvykRIDEiYp1LhkJfFjtFQpiSYCXA0DN6tmljX
eEF/VxOPHKbTIQMMgzWaQxobSM14CoXUqKQTiGMDcx7c+RPDDRzIsZECeJ0YifWbBRPvEST7Jhzv
3UY7M4wypwrSkVGUV4L1svHw63w7cBd0EMLoOWtxJKZFLaCTAQUUELYulCJQlzWBhqWL9o5015/m
KgTk6AWMqm5ATCWBUsUEStiUW8ANoLrVt+ETdRHF5EiV3uDKHBALGRnTaYQIMRF6qQUcYfAiW3IY
YkdTKW0cK5ATCsWCDrWLQOFGQPsSo4hdCkQIWiJiVDBTEzQsjxYCgqJYRLMGGIlxUhg5YeZqZmCG
hyktNGv0QhF8rgvJEqqCqCmiyOKPbXbcS4ljQNjU1ZQkTG23wpEzObVgOCj2NKmqFzB7gdhizu6y
pyPkhaMLrh9GSGqRGfYaDVzqajkQsiHIYqcSJzL1HKEFBJYc+ciNuw0dMCo0aj80GOdSs4LiIm5k
Od+u2wlKcEJPjkaE8BzqEBAyJFjI4cJFtzc3NSJe6kti40hSWxv1NUBMOviljykZYceW2GZzhlSb
Mclpwtoh24WmVoc48pMgJqWXiMZEKDlTQ1Jkq3mZkK6NoYDzQwwIChEqMYHi45oSM3KGjB0DADVB
DMEJ4GJvv6KEimYwMCtAqTzLOX5HaTu6llF6I5CTI0SXqcdsM1btFPjlgTZINhBkPN1KKVhYTCCw
ZEzCg7zvkKB2DPN4zFrJIlJfJCOXM8W2BcLLyOZwGgKEjU7rcM5R3mqvjcXuGFFB+8OATzqZGE8B
qkhiXbGMSZxSKDCJ7ZCO/G094tI1FCTQl2zvEKpQlls5YiMVGQLk5ThGFrZEQD5/NDzEpjQ51Mam
WguWSHXnI7ZEd5so2K5EdZFrRCvUsZG5R1TExTDsMz0ICSLxMsTQw6hMz2zHGVienZ8Z3AUNMjAm
WM8sNiLUJFCGIwpQpHlMiUnXskPE0PE5pgfQgnbJnOqm47/BlWHfqo5L5Y1LSeiUYd34SHHXQBZF
ZyjUKSQ6BOx6ImXFGQYdcJ/beMaUdyigMoypBTpILqiVl876Zhi4FFPrODFP+lk7XYtT8Xx479Qm
OKviqB3BwSjyW8H1cAhaGcQmDqF5kCSAYFAaEMLQcEPIgKhImoBgoYLh3mRm7D2ICILcx1wGQQRG
RYAsJ7yBiAVhAxgdPWHbkqsYoo9+y1YrEBfrKAsWwgYxjYX7AtXbcIL/Qu+wxqX06uAfaC5O9I/M
xlmmgTSLUGPnmxiIBtEOaO+R80bbSeY1od5Vf2vw9w/D9jm3+NYQCAEhJI+p+Q12/QzsY0Sv6+6a
ZdATy/gIb3e74STKQ+5j1CYzVBfVeBfi+x+zBOBg+yfgwLvaHrf/NWwtD6gpoxzb57d5Y7Qsv1mx
rAqpeBPYJuEztAoan1N11+medsTVIFYMZWLcy3lAUoyZjvDXO2BWyaU182j8tPz+f0/Oheo8lCRt
9ZH97RvTRoOMFe9RY9L/CynakcFLsTkpFNhDq+vTy9DTx5F18fzgaj5YSQISLJkXHSLCy/wx7Evq
uzTBU7vKj6xqVA7/qIEJSty95o4DYE62D8dN3DV84vhZ03yb1JF+l20GH5VEs7QSGnUWAjDL0TLY
xOfD8h+VJx/E8Ch3H0b/dnFH0dYWKKik1RZAIkCgYSGjoGOlsqcoXaf1Ttn1Z2RuwlLJGwk8zOHe
ua+tVL2ZbdK/QdiOg9ClUlVjaGmMGD4gssGJOj0TDCQZPfO5Lg8lGetTicVVVR7s/Hv/AlLAOHCn
ATYhOUsyZHpObstcllaQIDS5JGQi5EfnNpkicUR+g0fOeoYkfEfmHNalPztQiJoVKa+Nbn5zEYox
+g0NUP0uXO8TU+/7rXFkCkzEgdT5j4uBC5+lcUmoLyZQ/wAA0dCQbzORxFvgDpGhUZv3FTiIMgYb
gzilYhYH0kNUutDF/t9vbpk7KJ+4aloeuBoM6YC0zhiYsmdCqWBmE+TmVq6dscCqFz3ECnIlrkYY
ZClIiYWJ9p9jLELAIKHTwhNHxQ0KjICgkRECfq6oVCCKTSI0Zt0RlvIA5SChUWAvvNatlmQWShJL
vEMSV8XrR0UDKZcklmeGUwNgxiTLQQHfuzz0LMH5/umZ09/+il/Cxd8zw5kMZ49C9x4EzMeGkqTL
i3CxdJjlzAU9eMSw6nsiMRoTQT0jFTY7UX0kgQCOp7TUoa3FNRzU70MD6ODTXUXVfmy1pJO0Vf2d
d0vNcIYNSnKUPsYHoua5IFI8/1C6w9qnQeHGxWCrTioi/96KGNS5QxRmbYKqD0v2nrcaZ3ZQZaWV
8xSAhMR33Q5WLl3zVLmn8kC4HKp4S5sttDepXEzwdlx6+1EHeVLDvvLisBShgcUPaZVMCJQNaGf1
eEzy31NC5RPIyZBkXAt8d32XWzp71wZwbiAGmXg0KW0BQcUO+6cc6GLWFqE3AhjAWTJsfLN3a/E+
xk4ndI5qBrUgAD5EM4gYI+75R96DfDFTdAA5dp2ujXpmT09TND3WWPbyt1MylRqCI7sMPoyrSZRd
81JJEiCBMYMVi4nM5nDELuSmFew2aSg1yZ+DGO+2YvlgbMAxAcsEFJcI5S1asQjcKUwGMpDiKbZh
LqcseW7kviSnIzo4zFYZDOI3blvPxYllpijiM0GckNodC07lh0x7UHBjYeMMNx8KEK5iNDskCYVw
AC8LiVES+GgpKk2prcgNliTYrfAKcs5GZJhiKAtJbE3qFGtrUgvPI7r24hjZDc7yccvojp1uFbVF
H/vMpO2lKAWJkRgc5IswYilxM0BEHRCGJbNrdCMTAFEXfR9HvME7BPSeLZD9VWrtYT7pgRdX3Q3A
CK1dxweRjWbZT9OcbRnhEJkLB4W35Zk1MpOZkVZFqs653q4Vje9anr9IqnunjIQJuOOjTQTzKHx6
HrNq+uky5seMTzMRvNadfPbGGP6++UYrlU8zHc0G4Ht0EEFTWUuq/KjPrOCA0g+UQaELOhSnwyNI
5IRjRLycStzDWclqURjY6RSik0cqbrYSG0I/50m1ZFiZEWbwqZ0CsORy5eWimZBkwacrSxlRW8c5
OnQ6HdlEm/l4mQh6Shw9VO7GaqvEOzTflMNYaey43oBoOo2yvBzRhxEZZZQfMDuEGA0Kl2ObOGbT
z2zDP27Y+YTAyoz9J7k2xejhDJDu4eRDCxoQcyDc3V1PbyOKCJE4M1Rq6B95AQDTaOAAulfQswUD
VY2tQWCGZ65cpxl4+pgvoSGsE4eyu2Ww0OxoBwQEMAhZQaBEJSkhQtQKYSQiSvUHSu+ppqaGZBQD
FzPDynCY7TcIquEmUsh1ISxhKPlVE6jSQ1lWQyC6KVRay6AqraIaWUwI2R2kawXmkXUQmlQAJwSF
Bf5vqkJ/JMN9QVQx99ydQggIMASOa4SyTNH3UOiAe0deEgVEesmfrLJhwju+DqnYQPjiARIAm5nI
nWHc5ieEogMtWJJUlST8LJDGBgWGxsIQaEixiFtke8ft8z0n5sn7+WIfAqfE+XjbJ5Yy7ioc8ZXL
5qRy4UF0jwsZxTg6Ak606HrMYdhA1JY0wE3HdRnUjBd3LKaJdRKaanu1N77Z7cT3czC2liiM9SIe
MBZ9qE4YHudoK4k9ImjAa7hK9IhXJDu4mi8JmzRcP2WCIBjEeA206QSG1EwKK0RwVSe8Cxk0NAuP
eVSKNurIbC5oFzEXeSpozbAGJaYCuKy9mOVZjtQKuKC4RlCGNYHwORk9oigzw8mMYNqd+FxgGD3z
0z1jAmz5iAcxZI2BOGl7mhtUk1BaG5TJs4zRAXjFcgo7DqZhiLJnORAopRKVA38XIvOGymoKzcrx
gk5jOrZwEVsAQ6HVYOMGphjZEiCAi2BHCBqCkIQtIxOI1DIXvRpSSW2VR3NEIHSXeLAGgV7/Tp9z
EADWt4bN1Q7GtfTj4OVIdYCSUPLtEAioQ8qHYtPoUqBAkO7BCkql+4UnJcUW4RDSJsQdlPKmJWR7
z8UEPCb6I4DgrwCGJLXX/v8Y5ECWY4rj9lAPaGeHU8ZwIF2WDzxl4iRTzOgHvT4S6aKbvEs6/rUg
9i7SCr0H6xgZmJYpgGk5b+7hujhQkQ45MzQQXsT0XoRmNT+DPeumDKskJUhYfhDzDSEgsSExtl6r
dO4OukC4N+mg2U3o9tB8m8wNAI+gkIWjBux812QrLB1CguTJUGNgPPEHIBQ2RHqNpYhVzdWYzfH0
+xEWoFI8YRTxgS1FBczcHuag9DbYdBoFYnT2Uyeqk6U6dCrgDgsB3Hd0AazqHCdpWWUbAtAwYTyC
iULMZApEdU4kREjxajfHM6dpRaBD4yOsSN9lCG33PMUQpCQdUOMa2NjVCQpq5zxhKxnNWJKAD7Qx
AWQICCZlQrDmW9sOgj/wvjDz0JCWgYSvtpIccBGEyELRnZIkhdmD0UweAAoEZLG1QQrZp+UdTe9l
06L7MuyY0vXhkTjCB4zdO5hJqfHbODFYWqEd3rgwGUXMThfoc8YMqKFJQM+G1WJSDm7jpCxjyzQe
InDOX3HnJZh8kg2m4OmBv/P6AjsEl/TnBtAm20SRq3PYLh7O+qOTmCGc7/Q7Qmg0qgtWGXf2iPPB
bGWhBZ0tETnENwXjLJxHUwhIgZOSeBuTbZPS0FchANQg0nH8DNS4KgigCOUI+kDAkSEdroBij2Dz
6ZCiMPR6ZQ0QVPCUcQvC+AY6YUyYXh77vL3BONBvLZnc+QRM6BESoYCUxCr1i+Ql8kSDzyAcGbet
NQRxUROFPVeMY21iwsUKCdDCNp8LmqSpeXy6zQobtimkLNbpJlzMbKgoF9w2hugbUgaBh2+MJTXA
4Yb4HpGVBiwU2pAEkEYQUE4GxDaDrIUILKTmHxoAUS6+gVBF1ACkIQcwBF3KraFgAFplafiiv3wO
0wa0VLDhdAc7FthloXCmX8Y67EaRFSL94ZnQdsFCB1tgkIGuqUoLhQiwIxjGA9IfAb/QMjydNFk8
c0xKw0oOc8T+Vsb1r8UkEajyMjDI9UfMSqqpHWJWgWeXsLtqQqyGoloAHzCLxRKIHCmMDTBTTCh+
skfiC4TMoBaUOqOtRsOz82VV8PN4rM19AiEgSLIBsFKE1R5kOsWgD40LALWBqOyLLKxJbn2rWggA
h4EzVYIkcl4NQ2M1HyNShOkSapRX7DNhkbW3tMUHtMhHwTBS1zXQOU4mHZfsrNEC7UqrYgZrZ7y+
GmiWyAXIchtzDoA88CqMRI3pLOSlKoXBznltQJJC54UK9UWkmURD5LWaEB1ctcPrMGIJ0QWsF9VV
veNXBbQhdQS+c5XHFQ3m0MgvwRLuEPEuOoRpjWsqjD1twtwZL0fp1294tgaVxRsaGNAmJ1zlYhEv
OchOL9mMOkOI8EDw3TKgXNc9bQDlJNuhEVCMFJ1FjZCjO1cysRiAHdGApyEPdIEC7wD+lsFcFTAU
gNgcb0oeLbahek5gIpgRDt4cFCVuSWx5YXLohsbiHiElUgeO8UE/IJE70hvhr7D0ipEg0mAuK2t/
azjMlto4w5wdAYJ0Fq2Zkam3eVL9fPVbQ7Wy/N6MkdiaBBtaIFfMShXHHwCUcgAJosWvGJq5HSYu
LmImQyKrBTnpayhVGQGNkYBXvBO1PKeYbBLAQKRKDLBKN9qG83bwd6WE8h0L6vYuHMgf/vRbCoUi
zzPJF8iEYlqe5KfCc3mKvrYb7dmloSQxpNgWzVYmYuLKBfbcEBNDDk1wUwesRNRgeYNV2PS5nO5t
FUAMo1eI8AedK5S+6mh2oJiklMpEZS+9TxR9BjYhbUVE2Xt7okhDRN3OFiYlx0qWnk5/VPbZ73vF
CWMCidfQjzsAXdIW7PUXkL4YysNrbBsQ6IW0X815CbQiQMthnC5HvoPaTnFsA7InRGQJGTbqmIF/
TM1C8CIRBG/fvmbfwHLETRshHKIypNiBTDrRkvwDcswLcPK56ch0iRL3p6Az5oVUTLj4nUFFeKkL
JBuZ8O4yb8I6M2xT8IN9XG/2v0nZyUVRGQM1ZlLSSAbNTBB0CAnYTYVUtkSKgMlcaScNFYvZxcMR
ggvJmHFVk1pNQgLTZHxizFgnZRNApnIYhLLOBEQAON2YSKwgqvdsNwR1NTWbUsTlEdKViPMZm/IG
a1OUeVLwpx3VnIb3ehgAgCGMZNXADGA4WIuZww1OQGk5AM1vOLCbQN0JSxJokITVRHV1bRHHpU5d
W1kF96QHUbhkleJLDNrI1rXQdCFGgGgUFhNImoDSbwto1EbbTl9Ol6pSkO0T5s1rZscoVVBKSIOM
IjrtQQIWsHwxSgAY1mGjWEbAN8jkB22bto9tZbCXte8bBMAM4GEQkHM3iNQevXMOlQLLOwettlUk
XJXNaZEF2dE5PNUnMpCHMoUlUhC1UmIWyVeWiDmuBJe3YDU4XVv72Til2nlMwd8+EXgL1VsE/J1Y
75skhEjIE1npT33KxP4JDOXqrtalxfBB6OblHTYI1DPlWzFVBfmbEMKm243e4PcI2qSCn2c+ylNv
KwLVDU6EK9eGHKPr1lBMoA20UCP4wmksaIwGXU7RINgL1lCTJuEC6QaK+h/agVoZCiwYMbVgjYuJ
YLJjrgDej1nuPeMnIHhthDWcJGumWmC+0sdsOEuUQ7e2zwndIpaKIEAgHKrLTRRUMkAtAhr7ZcY7
kEWEGjBPFC0hUOIUQ4NLyy5DIZDNPE3faeIuo8TQKQukRNHFfWTBURfdLtMIlgKFXvaTGks5lTFf
GGAMYTk0EfH26oIOg+72kEHHbDuuSZNjXJY/WqGuc8zZj5FZE2DSlDWpf/fQ+s0H/xdyRThQkPFC
lS8=
Attachment:
new-wiki-syntax.png
Description: PNG image
Attachment:
signature.asc
Description: This is a digitally signed message part
| Thread Previous • Date Previous • Date Next • Thread Next |
{kind=link}