maria-developers team mailing list archive
-
 maria-developers team
maria-developers team
-
Mailing list archive
-
Message #11966
Re: Performance of index intersection
Hello,
More thoughts on this:
Let's consider a query
select * from t1 where key1=1 and key2=2
let's assume it uses index itnersection.
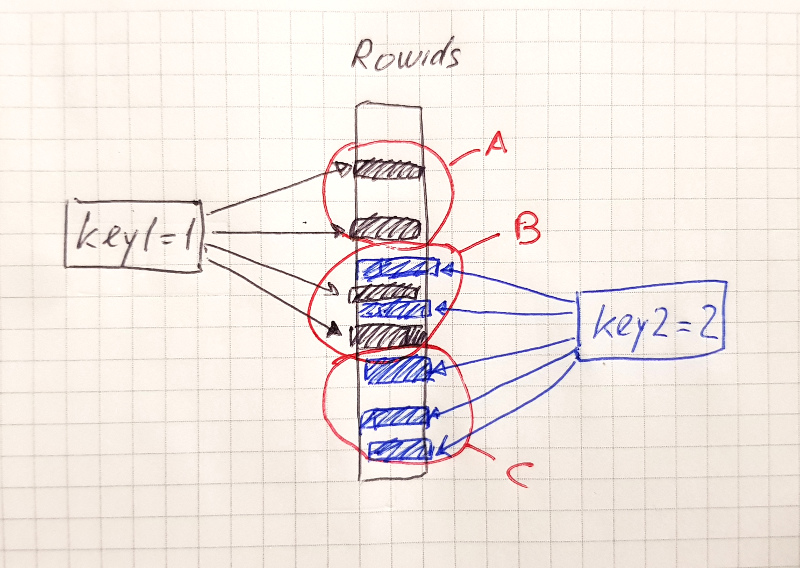
Check the attached picture. It shows the table rowids at the center,
key1 on the left, key2 on the right.
There are three zones:
- Zone A, where rowids matching 'key1=1' have no overlap with any rowids for 'key2=2'
- Zone B, where rowids from two scans overlap.
- Zone C, similar to zone A but at the end of the scan. Here, rowids matching
key2=2 have no overlap.
The current "merge-ordered-streams" algorithm takes care of "Zone C".
the code will return EOF as soon as one of the merged streams has produced EOF.
Now, let's look at Zone B. Here, the code would scan both indexes forward
and search for records with key=1 that have matches with key=2.
The search forward is this loop in QUICK_ROR_INTERSECT_SELECT::get_next:
do
{
DBUG_EXECUTE_IF("innodb_quick_report_deadlock",
DBUG_SET("+d,innodb_report_deadlock"););
if (unlikely((error= quick->get_next())))
{
/* On certain errors like deadlock, trx might be rolled back.*/
if (!thd->transaction_rollback_request)
quick_with_last_rowid->file->unlock_row();
DBUG_RETURN(error);
}
quick->file->position(quick->record);
cmp= head->file->cmp_ref(quick->file->ref, last_rowid);
if (cmp < 0)
{
/* This row is being skipped. Release lock on it. */
quick->file->unlock_row();
}
} while (cmp < 0);
the quick->get_next() call (after several levels of indirection) do this
storage engine API call:
handler->index_next_same();
And the question is whether it would be faster if this call was made instead:
handler->index_read_map(key_value, rowid_of_match_candidate);
The answer is that it's faster to do a jump when we will jump over many
records. When we jump over a few, it is actually slower than making several
index_next_same() calls. The first reason for this is that doing seeks will
break InnoDB's prefetch buffer optimization. There might be other reasons.
I don't have any idea how one could predict the jump size.
As for Zone A, we could jump it over with one jump. If we first read the rowid
from "key2=2", then we could already use it when making a lookup with key1=1.
But what if we first did an index lookup on key1=1? Then we will miss the
chance to jump to the first rowid for that one sees for key2=2...
If we assume that the first jump is more important than others, we could just
look at the first record in each of the merged indexes and then feed them all
back the maximum rowid we saw as the starting point. This would let us jump
over zone A.
I think, implementing "jump over zone A" is easier than inventing a way to do
jumps while in zone B. (And this is actually what your idea was).
A different question - are there any example datasets or queries we
could try this on? One can of course construct an artificial dataset and
queries but it would be much nicer to try this on a real dataset and a real
query.
BR
-- Sergei P.
On Fri, Sep 20, 2019 at 12:31:10PM +0300, Sergey Petrunia wrote:
> Hello David,
>
> On Mon, Sep 16, 2019 at 09:07:09PM +1200, David Sickmiller wrote:
> > I've been using MySQL/MariaDB for two decades but have more recently been
> > working with Elasticsearch. I knew to expect an inverted index to speed up
> > querying full text fields, but I've been surprised (and a bit annoyed) at
> > how fast ES can query structured data. (In my case, I'm largely looking
> > for intersections of a number of varchar fields with lowish cardinality,
> > e.g. WHERE country = 'US' AND client = 'Microsoft' AND status =
> > 'Completed'.)
> >
> > Elasticsearch seems to have several things going on, but I think a core
> > aspect, to use RDMS terminology, is that each column is indexed, and index
> > unions/intersections are used if the WHERE clause references multiple
> > columns.
> >
> > I've heard that MySQL/MariaDB has the ability to merge indexes, but I've
> > rarely observed it in person. Googling for it yields a bunch of
> > StackOverflow posts complaining how slow it is, with responses agreeing and
> > explaining how to disable it.
> >
> > If I'm reading the MySQL/MariaDB code correctly, it looks like MariaDB will
> > intersect indexes by looping through each index, reading the rowids of all
> > matching keys and then, at the end (or once the buffer is full), checking
> > whether each rowid is present in each index.
>
> There are two algorithms:
>
> 1. index_merge/intersection
>
> This is implemented in QUICK_ROR_INTERSECT_SELECT.
> It is applicable when rowids from each source we are merging come ordered by
> the rowid value.
>
> This requirement is met when the scan over a single-point range. If the table
> has an index defined as
>
> INDEX i1(col1, ..., colN)
>
> then index tuples that compare as equal are ordered by their rowid. That is,
> if one does an index scan over
>
> (col1, ... colN)=(const1, ..., constN)
>
> they will get the records i`n rowid order.
>
> QUICK_ROR_INTERSECT select will run the scans on all merged streams
> simultaneously and do ordered-stream-merge on them.
>
> 2. index_merge/sort-interesect
> ( https://mariadb.com/kb/en/library/index_merge-sort_intersection/)
>
> This is implemented in QUICK_INDEX_INTERSECT_SELECT.
>
> The algorithm doesn't assume that the input streams are ordered.
>
> It scans all inputs and puts the rowids into a "Unique" object (think RB tree
> which overflows to disk). After the scans are finished, it can check which
> rowids were produced in all of the inputs, and those are in the intersection.
>
> > I wonder if there's an opportunity to speed this up. If we first read in
> > the rowids from one index (ideally the one with the fewest matches), we
> > could tell the storage engine that, when reading the next index, it should
> > skip over rowids lower than the next candidate intersection.
>
> This is a good idea, neither QUICK_ROR_INTERSECT_SELECT, nor
> QUICK_INDEX_INTERSECT_SELECT do this.
>
> > In the best
> > case scenario, I think this could enable InnoDB to use its page directory
> > to skip past some of the keys, improving the performance from O(n) to O(log
> > n).
>
> Agree.
> If the scans being merged produce data with non-overlapping rowid ranges,
> then things could be sped up. I'm just wondering how often this is the case
> in practice. Do you have any thoughts this?
>
> > That said, this is all new to me. Maybe there's an obvious reason this
> > wouldn't make much of an improvement, or maybe I've overlooked that it's
> > already been done. However, if it looks promising to you folk, and it's
> > something you'd consider merging, I'd be willing to attempt writing a PR
> > for it.
>
> BR
> Sergei
> --
> Sergei Petrunia, Software Developer
> MariaDB Corporation | Skype: sergefp | Blog: http://s.petrunia.net/blog
>
>
BR
Sergei
--
Sergei Petrunia, Software Developer
MariaDB Corporation | Skype: sergefp | Blog: http://s.petrunia.net/blog
Attachment:
index-merge1.jpg
Description: JPEG image
Follow ups
References
{kind=link}