maria-developers team mailing list archive
-
 maria-developers team
maria-developers team
-
Mailing list archive
-
Message #07575
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
Hi Elena,
I tracked down the issue with matching files and test_runs. It was simpler
than we thought.
1. I was using the index in the array, rather than the test_run.id field to
identify test runs. Sorry, that was my bad. I changed and reuploaded the
list:
> https://raw.githubusercontent.com/pabloem/random/master/matches.txt
This accounted for cases: 148470, 148471, 148472, 148473, 148474, 148476,
148478, 148481, 148482, 148483.
2. The other 'false misses' happened because there are earlier test_runs
that match the files:
> 148467 - win32-packages_3172-log-test-stdio
It happens that test_run 100940,101104, has the same platform and build id,
so the file is matched with it earlier.
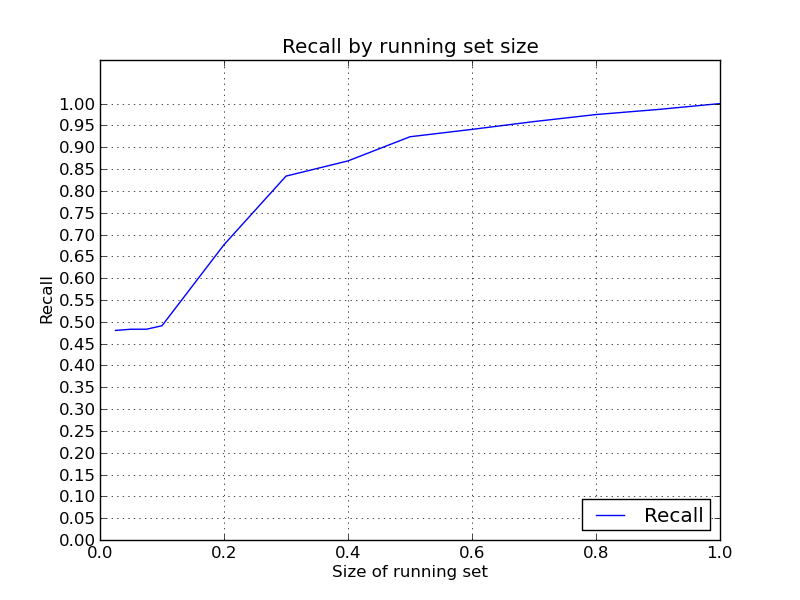
By the way, I just ran some tests with running_set size 30% and the results
were quite consistent around 80%, even for long runs. Over time it
decreases, albeit slowly. I still feel that a lot more consistent
performance can be obtained with consistent input lists.
Regards
Pablo
On Thu, Jul 24, 2014 at 5:00 PM, Pablo Estrada <polecito.em@xxxxxxxxx>
wrote:
> Hi Elena,
>
> Thanks. I hoped you would have results of the experiments involving
>> incoming lists of tests, as I think it's an important factor which might
>> affect the results (and hence the strategy); but I'll look at what we have
>> now.
>
>
> I have them now. There was one more bug I hadn't figured out. There are
> still a couple bugs related to matching of input test list, but these
> results must be quite close to the expected ones. I did them with 3000
> rounds of training, and about 1500 rounds of prediction (skipping all runs
> without input list).
>
>
>
>
> Although the results are not as originally expected (20-80 ratio, I feel
> that they are quite acceptable.
>
> I will see what we can do about getting reliable lists one or another way;
>> certainly the log files are a temporary solution, but it would be nice to
>> use them for experiments and see the results anyway, because modifying
>> MTR/buildbot tandem and especially collecting the new data of considerable
>> volume will take time.
>>
>
> I understand, nonetheless I feel that this is a reasonable long-term goal
> for this project.
>
>
>> This is not to say that parsing logs is the best way to do things, but
>> apparently something went wrong either with my archiving or with your
>> matching. If you don't have these files, please let me know.
>>
>
> It seems there's a bug with matching. I am looking at it now.
>
> I've uploaded the fresh dump. Same location, file name
>>> buildbot-20140722.dump.gz.
>>>
>> I will run more detailed tests with the new fresh dump. I will focus on a
> running set size of 30%. I believe they will be reasonable.
>
> Thanks.
> Pablo
>
Follow ups
References
-
[GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-06-27
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-06-28
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Elena Stepanova, 2014-06-28
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-06-29
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Elena Stepanova, 2014-06-29
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-06-29
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-14
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Elena Stepanova, 2014-07-14
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-15
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-15
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-17
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-21
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Elena Stepanova, 2014-07-21
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-23
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Elena Stepanova, 2014-07-23
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-24