syncany-team team mailing list archive
-
 syncany-team team
syncany-team team
-
Mailing list archive
-
Message #00630
Re: Bigger database issues
Hi,
Thanks Gregor for the data drive/domain driven discussion, I was not
really familiar with this way of presenting things (I mean as "opposed"
to top down vs bottom up).
My suggestion is not however to change things but to see if they need to
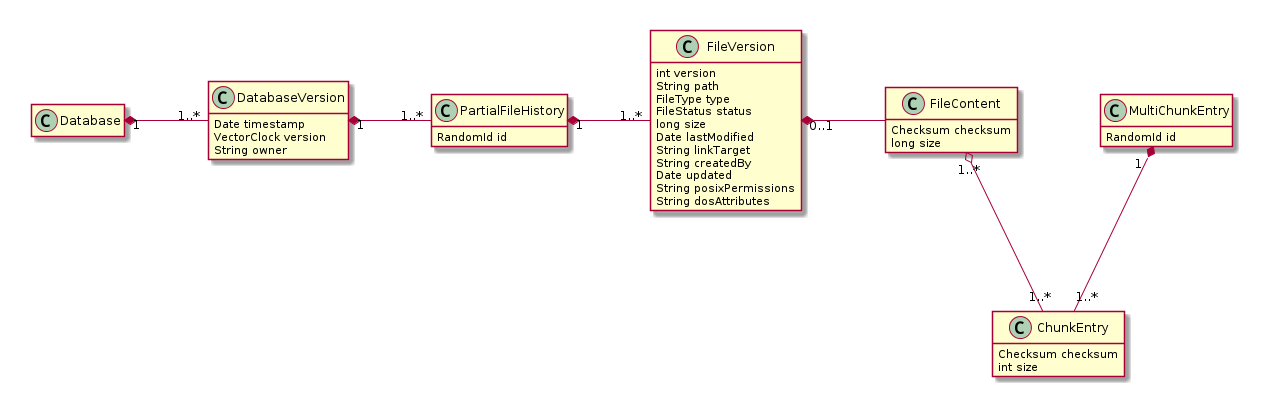
be changed. I experimented with PlantUML for this and ended up with the
class diagram attached to this email (with is PlantUML sources). It's
more detailed than Philipp's one as I tried to include attributes that I
considered strongly attached to each entity (each entity would be a
table in a relational db). It is also quite simpler because it removes
all the caches and redundant parts.
The redundant parts are needed right now to speed things up, but they
are tightly coupled with the "real world" entities, which gives a quite
blurry global image. If you look at the simplified data model, it's much
clearer in my opinion. This does not mean at all that a complex model is
not needed _in memory_, but persisting it _as is_ seems a bad idea. I'm
sure it's not what Philipp had in mind, but I like being Captain Obvious.
That said, I'm not completely satisfied by this data model because of
some minors issues (like the attributes of FileVersion which are not in
a minimal form) and of one major issue: there is no simple way to query
this data model in order to get the current state of the repository.
Indeed, you need to reconstruct the winning series of commits (i.e., of
DatabaseVersion) and to walk said series to determine the current status
of all files. This is mainly caused by DatabaseVersion being delta and
not complete commits. In the current code this is handled by a full
database cache which induces more or less a full duplication of the
database. I'm not sure how this should be represented in a persistent
state but based on what is done in most of the version control systems I
know, I think we need a CurrentDatabase entity which aggregates one
FileVersion (the current one) for each path of repository.
>From this on disk/in relational db data model, each operation can derive
what it needs in memory, based on some specific DAO if needed.
What do you think of all that?
Cheers,
Fabrice
Attachment:
datamodel.png
Description: PNG image
@startuml
hide empty methods
hide empty fields
class Database
Database "1" *- "1..*" DatabaseVersion
class DatabaseVersion {
Date timestamp
VectorClock version
String owner
}
DatabaseVersion "1" *- "1..*" PartialFileHistory
class PartialFileHistory {
RandomId id
}
PartialFileHistory "1" *- "1..*" FileVersion
class FileVersion {
int version
String path
FileType type
FileStatus status
long size
Date lastModified
String linkTarget
String createdBy
Date updated
String posixPermissions
String dosAttributes
}
FileVersion "0..1" *- FileContent
class FileContent {
Checksum checksum
long size
}
FileContent "1..*" o-- "1..*" ChunkEntry
class ChunkEntry {
Checksum checksum
int size
}
MultiChunkEntry "1" *-- "1..*" ChunkEntry
class MultiChunkEntry {
RandomId id
}
@enduml
Follow ups
References
{kind=link}