maria-developers team mailing list archive
-
 maria-developers team
maria-developers team
-
Mailing list archive
-
Message #07585
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
Hello Elena,
Concluding with the results of the recent experimentation, here is the
available information:
I have ported the basic code for the 'original' strategy into the
core-wrapper architecture, and uploaded it to the 'master' branch.
Now both strategies can be tested equivalently.
Branch: master <https://github.com/pabloem/Kokiri> - Original strategy,
using exponential decay. The performance increased a little bit after
incorporating randomizing of the end of the queue.
Branch: core-wrapper_architecture
<https://github.com/pabloem/Kokiri/tree/core-wrapper_architecture> - 'New'
strategy using co occurrence between file changes and failures to calculate
relevance.
I think they are both reasonably useful strategies. My theory is that the
'original' strategy performs better with the input_test lists is that we
now know which tests ran, and so only the relevance of tests which ran is
affected (whereas previously, all tests were having their relevance
reduced). The tests were run with *3000 rounds of training* and *7000
rounds of prediction*.
I think that now the most reasonable option would be to gather data for a
longer period, just to be sure that the performance of the 'original'
strategy holds for the long term. We already discussed that it would be
desirable that buildbot incorporated functionality to keep track of which
tests were run, or considered to run (since buildbot already parses the
output of MTR, the changes should be quite quick, but I understand that
being a production system, extreme care must be had in the changes and the
design).
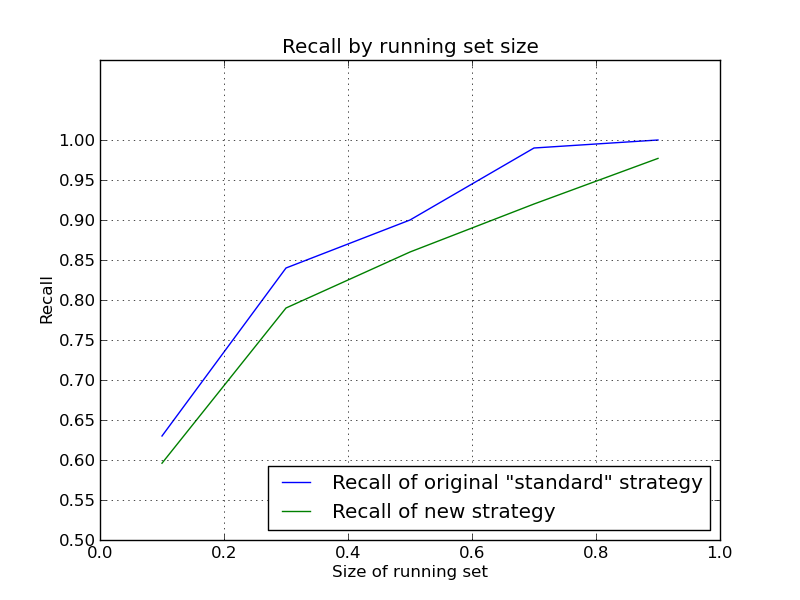
Finally, I fixed the chart comparing the results, sorry about the confusion
yesterday.
Let me know what you think, and how you'd like to proceed now. : )
Regards
Pablo
On Sat, Jul 26, 2014 at 8:26 PM, Pablo Estrada <polecito.em@xxxxxxxxx>
wrote:
> Hi Elena,
> I just ran the tests comparing both strategies.
> To my surprise, according to the tests, the results from the 'original'
> strategy are a lot higher that the 'new' strategy. The difference in
> results might come from one of many possibilities, but I feel it's the
> following:
>
> Using the lists of run tests allows the relevance of a test to decrease
> only if it is considered to run and it runs. That way, tests with high
> relevance that would run, but were not in the list, don't run and thus are
> able to be hit their failures later on, rather than losing relevance.
>
> I will have charts in a few hours, and I will review the code more deeply,
> to make sure that the results are accurate. For now I can inform you that
> for a 50% size of the running set, the 'original' strategy, with no
> randomization, time factor or edit factor achieved a recall of 0.90 in the
> tests that I ran.
>
> Regards
> Pablo
>
>
> On Thu, Jul 24, 2014 at 8:18 PM, Pablo Estrada <polecito.em@xxxxxxxxx>
> wrote:
>
>> Hi Elena,
>>
>> On Thu, Jul 24, 2014 at 8:06 PM, Elena Stepanova <elenst@xxxxxxxxxxxxxxxx
>> > wrote:
>>
>>> Hi Pablo,
>>>
>>> Okay, thanks for the update.
>>>
>>> As I understand, the last two graphs were for the new strategy taking
>>> into account all edited files, no branch/platform, no time factor?
>>>
>>
>> - Yes, new strategy. Using 'co-occurrence' of code file edits and
>> failures. Also a weighted average of failures.
>> - No time factor.
>> - No branch/platform scores are kept. The data for the tests is the same,
>> no matter platform.
>> - But when calculating relevance, we use the failures occurred in the
>> last run as parameter. The last run does depend of branch and platform.
>>
>>
>>> Also, if it's not too long and if it's possible with your current code,
>>> can you run the old strategy on the same exact data, learning/running set,
>>> and input files, so that we could clearly see the difference?
>>>
>>
>> I have not incorporated the logic for input file list for the old
>> strategy, but I will work on it, and it should be ready by tomorrow,
>> hopefully.
>>
>>
>>> I suppose your new tree does not include the input lists? Are you using
>>> the raw log files, or have you pre-processed them and made clean lists? If
>>> you are using the raw files, did you rename them?
>>>
>>
>> It does not include them.
>>
>> I am using the raw files. I included a tiny shell (downlaod_files.sh)
>> that you can execute to download and decompress the files in the directory
>> where the program will look by default.
>> Also, I forgot to change it when uploading, but in basic_testcase.py, you
>> would need to erase the file_dir parameter passed to s.wrapper(), so that
>> the program defaults in looking for the files.
>>
>> Regards
>> Pablo
>>
>
>
Follow ups
References
-
[GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-06-27
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Elena Stepanova, 2014-06-28
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-06-29
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Elena Stepanova, 2014-06-29
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-06-29
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-14
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Elena Stepanova, 2014-07-14
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-15
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-15
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-17
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-21
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Elena Stepanova, 2014-07-21
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-23
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Elena Stepanova, 2014-07-23
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-24
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-24
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Elena Stepanova, 2014-07-24
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-24
-
Re: [GSoC] Optimize mysql-test-runs - Results of new strategy
From: Pablo Estrada, 2014-07-26